code
baseline
- 预先存储矩阵Q(s, a),表示在状态s下,采取动作a,遵循某一策略预期能够得到的期望回报
- 仅适用于状态和动作都离散的场景,且空间较小的情况下
DQN
- model free(无环境模型)
- off policy(产生行为的策略和进行评估的策略不一样)
- 适用于离散动作空间,且维度不高
- value-based,仅有值函数网络(critic),根据值函数网络确定Q(s, a)
- 利用$\epsilon$-greedy策略确定动作action,给定$\epsilon$,每次生成一个随机数tmp,tmp>$\epsilon$,选取最优策略,tmp<$\epsilon$,选任一策略
DDPG(Actor-Critic)
- s: observation 状态
- a: action 动作
actor(策略网络:根据值函数更新策略)P网络
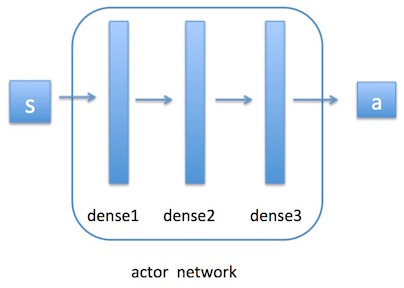
critic(值函数网络:给定一个策略求值函数)Q网络

- 策略梯度 Policy Gradient